
- A+
ElasticJob
为什么要使用ElasticJob?
对于一般的业务系统,如果使用Quartz或SpringTask即可满足单体服务应用的需求。随着业务的扩展,这两种方式已经满足不了需求。这两种框架的缺点:
- 业务工程集群部署,可能会导致系统的业务逻辑错误,产生系统故障。
-
Quartz集群方案可以实现定时分发,但是通过增加机器节点数量并不能提高定时任务的执行效率,无法实现任务弹性分片。
ElasticJob就是支持任务分发、分片、监控和扩容等功能的开源分布式定时任务调度框架
ElasticJob简介
Elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。
Elastic-Job-Lite
定位为轻量级无中心化解决方案,使用jar包的形式提供最轻量级的分布式任务的协调服务,外部依赖仅Zookeeper。
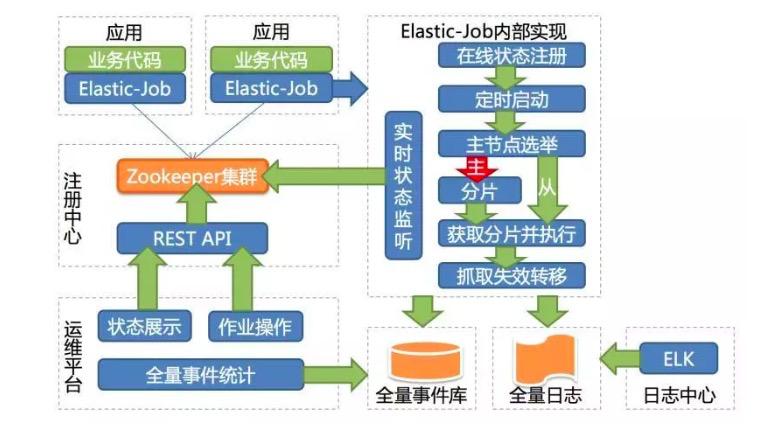
Elastic-Job-Cloud
Elastic-Job-Cloud以私有云平台的方式提供集资源、调度以及分片为一体的全量级解决方案,依赖Mesos和Zookeeper。

这次分享的主题是 Elastic-Job-Lite版本,如果有对Cloud版本感兴趣的同学可以研究下。
Elastic-Job-Lite 核心功能
通过上述Lite版本架构图可以看出,作业代码是有Jar包形式进行实现的。我们可以通过Java Api 、Spring以及SpringBoot形式接入作业。在后面会对这几种接入方式一次演示。
基本概念
- 分片
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。 为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。 -
分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系。
-
分片个性化参数
分片个性化参数即shardingItemParameter,可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
例如:按照地区水平拆分数据库,数据库A是北京的数据;数据库B是上海的数据;数据库C是广州的数据。 如果仅按照分片项配置,开发者需要了解0表示北京;1表示上海;2表示广州。 合理使用个性化参数可以让代码更可读,如果配置为0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
核心功能
-
定时任务
基于成熟的定时任务作业框架Quartz cron表达式执行定时任务
-
作业注册中心
基于Zookeeper和客户端Curator实现的全局作业注册控制中心;作业注册中心仅用于作业任务注册和监控信息的暂存,保证同一分片在分布式环境中仅一个执行实例。
-
定时任务分片
可以将原本一个较大任务分片成为多小的子任务项分别在多个服务器上同时执行,提高总任务的执行处理效率
-
弹性扩容缩容
运行中定时任务所在的服务器崩溃,或新增加n台作业服务器,作业框架将在下次任务执行前重新进行任务调度分发,不影响当前任务的处理与执行
-
支持多种任务模式
分别支持Simple、Dataflow和Script类型的定时任务
-
失效转移
运行中的定时任务所在的服务器崩溃不会导致重新分片,会在下次定时任务启动时重新分发和调度
-
运行时定时任务状态收集
监控任务运行时的状态,统计最近一段时间任务处理成功和失败的数量,记录作业上次运行开始时间,结束时间和下次运行时间
-
支持配置定时任务停止、恢复和禁用
用于操作定时任务的启停,并可以禁止某任务的执行
-
Spring支持
Elastic-Job-Lite项目完美支持spring的容器,自定义命名空间,支持占位符
-
运维平台
提供运维界面,方便开发和运维人员管理生产环境上已经发布的定时任务和注册中心
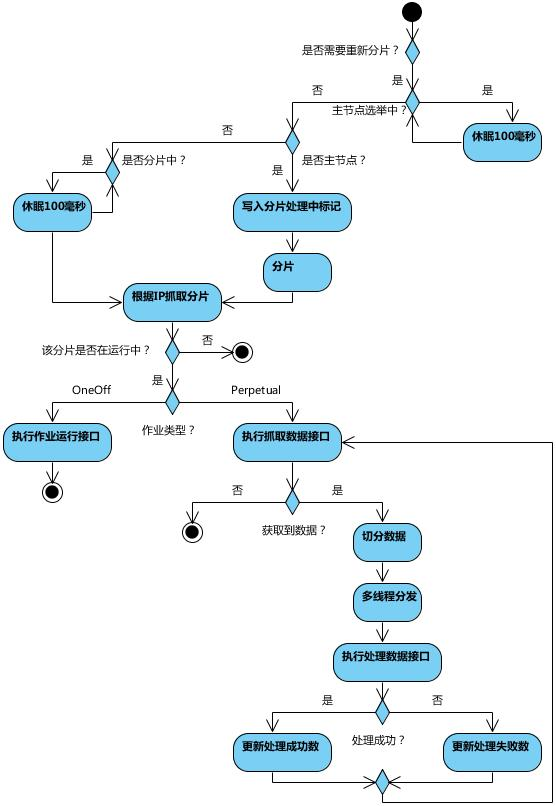
实现原理
-
弹性分布式实现
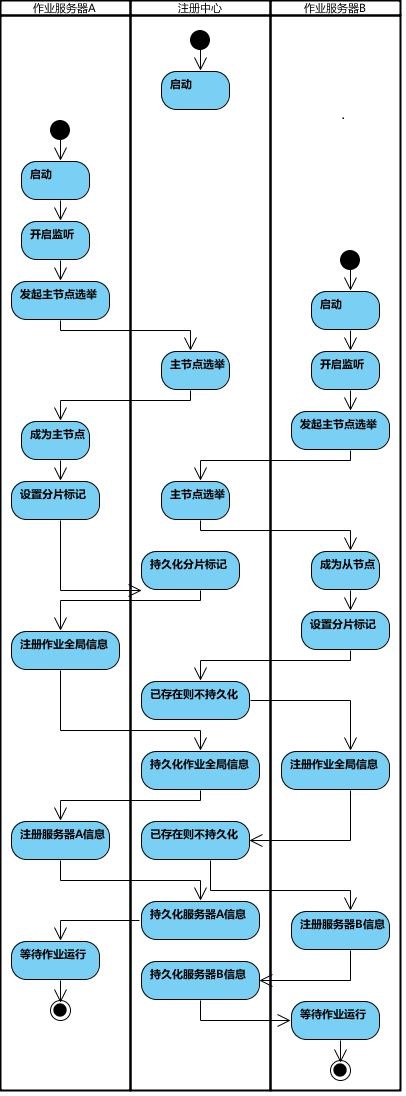
- 第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务选举完成,才会执行其他任务。
-
某作业服务器上线时会自动将服务信息注册到注册中心,下线时会自动更新服务器状态。
- 主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
- 定时任务触发时,如需要重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
- 通过4可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
- 每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
- 实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
-
流程图
作业启动
作业执行
功能示例
-
定时任务水平切分
可以通过任务水平切分的方式(id编号或者分区列等)处理业务系统部分数据,在数据处理完后,可以统一做汇总,这样的话,不管业务数据多大,都可以将任务水平切分各个子任务在不同的机器上进行分别执行,从而最大的利用资源。
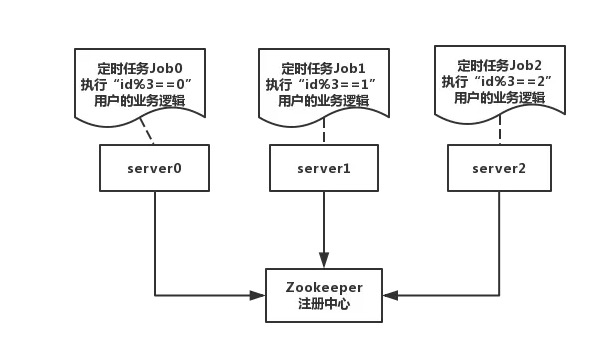
如上图,ElasticJob将任务拆分为三个分片任务,使用三台机器执行各个子任务,每台机器执行不同业务逻辑数据
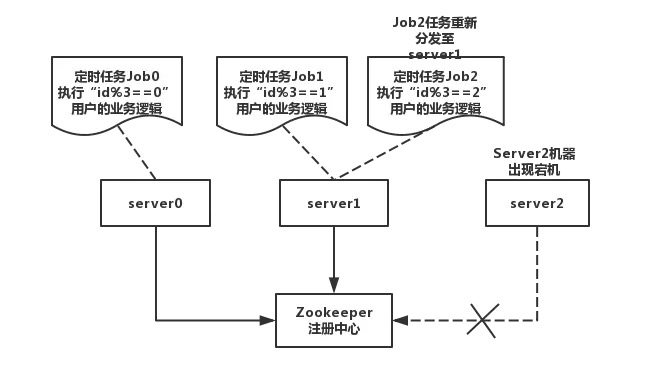
- 弹性扩缩容
在执行分片任务时,服务器如果遇到宕机或者故障后,elasticjob会有弹性扩缩容机制,会将宕机服务器上的分片任务重新分发至正常服务器上。如下图:
作业类型
Elastic-Job提供Simple、Dataflow和Script 3种作业类型。 方法参数shardingContext包含作业配置、片和运行时信息。可通过getShardingTotalCount(), getShardingItem()等方法分别获取分片总数,运行在本作业服务器的分片序列号等。
- Simple类型作业
意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
public class MyElasticJob implements SimpleJob { @Override public void execute(ShardingContext context) { switch (context.getShardingItem()) { case 0: // do something by sharding item 0 break; case 1: // do something by sharding item 1 break; case 2: // do something by sharding item 2 break; // case n: ... } } } - Dataflow类型作业
Dataflow类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
public class MyElasticJob implements DataflowJob<Foo> { @Override public List<Foo> fetchData(ShardingContext context) { switch (context.getShardingItem()) { case 0: List<Foo> data = // get data from database by sharding item 0 return data; case 1: List<Foo> data = // get data from database by sharding item 1 return data; case 2: List<Foo> data = // get data from database by sharding item 2 return data; // case n: ... } } @Override public void processData(ShardingContext shardingContext, List<Foo> data) { // process data // ... } }流式处理
通过DataflowJobConfiguration配置是否流式处理。
流式处理数据只有
fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。如果采用流式作业处理方式,建议processData处理数据后更新其状态,避免fetchData再次抓取到,从而使得作业永不停止。 -
script类型作业
Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。只需通过控制台或代码配置scriptCommandLine即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息。
#!/bin/bash echo sharding execution context is $*作业运行时输出
sharding execution context is {“jobName”:“scriptElasticDemoJob”,“shardingTotalCount”:10,“jobParameter”:“”,“shardingItem”:0,“shardingParameter”:“A”}
Elastic-Job-Lite 实践
Java Api 方式
1、引入依赖
<elastic-job.version>2.1.5</elastic-job.version>
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
2、作业开发
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
/**
* @Description 此处演示的是简单任务
* @date 2019-07-28 13:15
*/
public class MyElasticJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
System.out.println(String.format("------Thread ID: %s, 任务总片数: %s, 当前分片项: %s",
Thread.currentThread().getId(), shardingContext.getShardingTotalCount(),
shardingContext.getShardingItem()));
}
}
3、作业配置
private static LiteJobConfiguration createJobConfiguration() {
// 定义作业核心配置
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder("demoSimpleJavaJob", "0/15 * * * * ?",
1)
.build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig,
MyElasticJob.class.getCanonicalName());
// 定义Lite作业根配置
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).build();
return simpleJobRootConfig;
}
4、启动主类
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
/**
* @Description 作业启动类
* @date 2019-07-28 13:15
*/
public class JobDemo {
public static void main(String[] args) {
/**
* 作业调度器
* 参数一:分布式服务的注册中心,配置自己本地的zk服务器
* 参数二:定义作业的核心配置
* init() 作业调度器初始化
*/
new JobScheduler(createRegistryCenter(), createJobConfiguration()).init();
}
/**
* 创建分布式服务的注册中心
*
* @return
*/
private static CoordinatorRegistryCenter createRegistryCenter() {
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(
new ZookeeperConfiguration("127.0.0.1:2181", "elastic-job-java-demo"));
regCenter.init();
return regCenter;
}
/**
* 创建作业核心配置
*
* @return
*/
private static LiteJobConfiguration createJobConfiguration() {
// 定义作业核心配置
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder("demoSimpleJavaJob", "0/15 * * * * ?",
1)
.build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig,
MyElasticJob.class.getCanonicalName());
// 定义Lite作业根配置
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).build();
return simpleJobRootConfig;
}
}
以上所有代码是基于Java Api的方式配置,配置结束后,直接启动Main方法即可。作业配置只配置了一个分片,所以只会在当前机器上运行,当前分片项为0,运行结果如下图:

spring配置方式
1、引入依赖
<elastic-job.version>2.1.5</elastic-job.version>
<!--elastic-job-core-->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${elastic-job.version}</version>
</dependency>
<!-- elastic-job-lite-spring -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${elastic-job.version}</version>
</dependency>
2、spring配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd
">
<!--配置作业注册中心 -->
<reg:zookeeper id="regCenter" server-lists="127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"
namespace="alibaba-job"
base-sleep-time-milliseconds="1000"
max-sleep-time-milliseconds="3000"
max-retries="3"/>
<!-- 简单工作配置信息 -->
<job:simple id="myTestSimpleJob" class="com.alibaba.elastic.job.test.task.MyTestSimpleJob"
registry-center-ref="regCenter"
cron="0/2 * * * * ?"
sharding-total-count="1"
description="我的第一个简单作业" overwrite="true"/>
<!--流式作业配置-->
<job:dataflow id="dataflowJob" class="com.alibaba.elastic.job.test.task.MyTestJobDataflow"
registry-center-ref="regCenter" cron="0 0/1 * * * ?" sharding-total-count="2"
sharding-item-parameters="0=Beijing,1=Shanghai,2=Guangzhou" streaming-process="false"
overwrite="true"/>
</beans>
3、作业开发
spring配置中有两个作业,一个是属于简单作业配置,另一个为流式作业配置,在Java Api方式中已经帖了简单作业的代码片段,这里将贴出流式作业代码片段。
数据处理实体类 Foo.java
package com.alibaba.elastic.job.test.domain;
/**
* @Description 数据处理实体类
* @date 2019-07-22 15:54
*/
public class Foo {
private static final long serialVersionUID = 2706842871078949451L;
private final long id;
private final String location;
private Status status;
public Foo(final long id, final String location, final Status status) {
this.id = id;
this.location = location;
this.status = status;
}
public long getId() {
return id;
}
public String getLocation() {
return location;
}
public Status getStatus() {
return status;
}
public void setStatus(final Status status) {
this.status = status;
}
@Override
public String toString() {
return String.format("id: %s, location: %s, status: %s", id, location, status);
}
public enum Status {
TODO,
COMPLETED
}
}
数据实体注册类 FooRepository.java
一般作业需要处理的数据是从数据库中读取的,这里为了演示在内存中虚拟了一些数据。
package com.alibaba.elastic.job.test.handle;
import com.alibaba.elastic.job.test.domain.Foo;
import org.springframework.stereotype.Repository;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* @Description 数据实体注册类
* @date 2019-07-22 15:55
*/
@Repository
public class FooRepository {
private Map<Long, Foo> data = new ConcurrentHashMap<>(300, 1);
public FooRepository() {
init();
}
private void init() {
addData(0L, 100L, "Beijing");
addData(100L, 200L, "Shanghai");
addData(200L, 300L, "Guangzhou");
}
private void addData(final long idFrom, final long idTo, final String location) {
for (long i = idFrom; i < idTo; i++) {
data.put(i, new Foo(i, location, Foo.Status.TODO));
}
}
public List<Foo> findTodoData(final String location, final int limit) {
List<Foo> result = new ArrayList<>(limit);
int count = 0;
for (Map.Entry<Long, Foo> each : data.entrySet()) {
Foo foo = each.getValue();
if (foo.getLocation().equals(location) && foo.getStatus() == Foo.Status.TODO) {
result.add(foo);
count++;
if (count == limit) {
break;
}
}
}
return result;
}
public void setCompleted(final long id) {
//设置状态,不让他一直抓取
data.get(id).setStatus(Foo.Status.COMPLETED);
}
}
数据注册工厂类 FooRepositoryFactory.java
package com.alibaba.elastic.job.test.handle;
/**
* @Description 工厂类
* @date 2019-07-22 15:59
*/
public class FooRepositoryFactory {
private static FooRepository fooRepository = new FooRepository();
public static FooRepository repository() {
return fooRepository;
}
}
流式作业配置 MyTestJobDataflow.java
实现流式作业配置需要实现DataflowJob<?>接口,且实现fetchData(ShardingContext context)与processData(ShardingContext shardingContext, List data)方法,fetchData为读取数据,processData为处理数据。
import com.alibaba.elastic.job.test.domain.Foo;
import com.alibaba.elastic.job.test.handle.FooRepository;
import com.alibaba.elastic.job.test.handle.FooRepositoryFactory;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import org.springframework.util.CollectionUtils;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;
/**
* @Description 流式作业
* @date 2019-07-25 14:58
*/
public class MyTestJobDataflow implements DataflowJob<Foo> {
private FooRepository fooRepository = FooRepositoryFactory.repository();
@Override
public List<Foo> fetchData(ShardingContext context) {
System.out.println("-------------------------------------fetchData: " + context.getShardingParameter()
+ "---------------------------------------------");
List<Foo> result = fooRepository.findTodoData(context.getShardingParameter(), 10);
System.out.println(String.format("Item: %s | Time: %s | Thread: %s | %s | count: %d",
context.getShardingItem(),
new SimpleDateFormat("HH:mm:ss").format(new Date()),
Thread.currentThread().getId(),
"DATAFLOW FETCH",
CollectionUtils.isEmpty(result) ? 0 : result.size()));
return result;
}
@Override
public void processData(ShardingContext shardingContext, List<Foo> data) {
System.out.println("-------------------------------------processData: " + shardingContext.getShardingParameter()
+ "---------------------------------------------");
System.out.println(String.format("Item: %s | Time: %s | Thread: %s | %s | count: %d",
shardingContext.getShardingItem(),
new SimpleDateFormat("HH:mm:ss").format(new Date()),
Thread.currentThread().getId(), "DATAFLOW PROCESS",
CollectionUtils.isEmpty(data) ? 0 : data.size()));
for (Foo each : data) {
fooRepository.setCompleted(each.getId());
}
}
}
4、启动作业
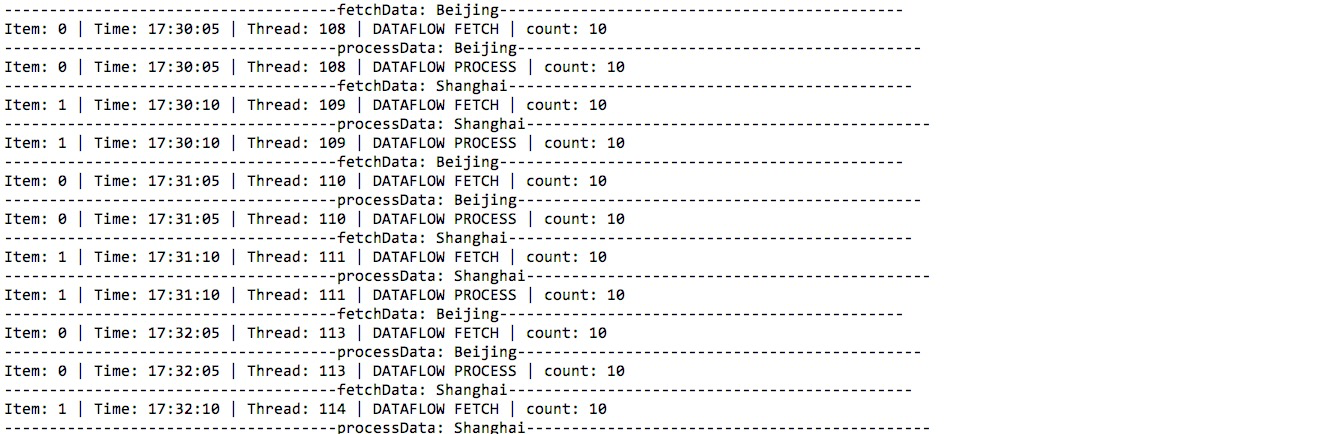
将配置Spring命名空间的xml通过Spring启动,作业将自动加载。
由于作业运行在本地机器上,只有一台服务器,所以两个分片会同时调度到该台服务器上。如下图所示,该作业为流式作业,所以执行顺序是先拉取数据,然后再进行数据处理。
springboot 配置方式
1、引入依赖
<elastic-job.version>2.1.5</elastic-job.version>
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
2、springboot配置文件
springboot中的application.yml配置文件中的内容,需要引入注册中心配置与作业配置
regCenter:
serverList: 127.0.0.1:2181
namespace: elastic-job-lite-springboot
simpleJob:
cron: 0/5 * * * * ?
shardingTotalCount: 3
disable: true
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
dataflowJob:
cron: 0/5 * * * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
springboot配置RegistryCenterConfig,在springboot程序启动时,自动初始化注册中心。
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnExpression;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConditionalOnExpression("'${regCenter.serverList}'.length() > 0")
public class RegistryCenterConfig {
@Bean(initMethod = "init")
public ZookeeperRegistryCenter regCenter(@Value("${regCenter.serverList}") final String serverList, @Value("${regCenter.namespace}") final String namespace) {
return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList, namespace));
}
}
springboot配置DataflowJobConfig,在springboot程序启动时,自动加载并且启动作业调度器。
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.dataflow.DataflowJobConfiguration;
import com.dangdang.ddframe.job.event.JobEventConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.lite.spring.api.SpringJobScheduler;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
public class DataflowJobConfig {
//注册中心bean
@Resource
private ZookeeperRegistryCenter regCenter;
//作业事件配置bean
@Resource
private JobEventConfiguration jobEventConfiguration;
//初始化作业
@Bean
public DataflowJob dataflowJob() {
return new SpringDataflowJob();
}
//初始化作业调度器
@Bean(initMethod = "init")
public JobScheduler dataflowJobScheduler(final DataflowJob dataflowJob, @Value("${dataflowJob.cron}") final String cron, @Value("${dataflowJob.shardingTotalCount}") final int shardingTotalCount,
@Value("${dataflowJob.shardingItemParameters}") final String shardingItemParameters) {
return new SpringJobScheduler(dataflowJob, regCenter, getLiteJobConfiguration(dataflowJob.getClass(), cron, shardingTotalCount, shardingItemParameters), jobEventConfiguration);
}
//获取作业核心配置信息
private LiteJobConfiguration getLiteJobConfiguration(final Class<? extends DataflowJob> jobClass, final String cron, final int shardingTotalCount, final String shardingItemParameters) {
return LiteJobConfiguration.newBuilder(new DataflowJobConfiguration(JobCoreConfiguration.newBuilder(
jobClass.getName(), cron, shardingTotalCount).shardingItemParameters(shardingItemParameters).build(), jobClass.getCanonicalName(), true)).overwrite(true).build();
}
}
3、作业开发
这里的作业属于流式作业,与上述spring配置方式一致,只贴出主要作业代码片段。
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import javax.annotation.Resource;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;
public class SpringDataflowJob implements DataflowJob<Foo> {
@Resource
private FooRepository fooRepository;
@Override
public List<Foo> fetchData(final ShardingContext shardingContext) {
System.out.println(String.format("Item: %s | Time: %s | Thread: %s | %s",
shardingContext.getShardingItem(), new SimpleDateFormat("HH:mm:ss").format(new Date()), Thread.currentThread().getId(), "DATAFLOW FETCH"));
return fooRepository.findTodoData(shardingContext.getShardingParameter(), 10);
}
@Override
public void processData(final ShardingContext shardingContext, final List<Foo> data) {
System.out.println(String.format("Item: %s | Time: %s | Thread: %s | %s",
shardingContext.getShardingItem(), new SimpleDateFormat("HH:mm:ss").format(new Date()), Thread.currentThread().getId(), "DATAFLOW PROCESS"));
for (Foo each : data) {
fooRepository.setCompleted(each.getId());
}
}
}
4、启动作业
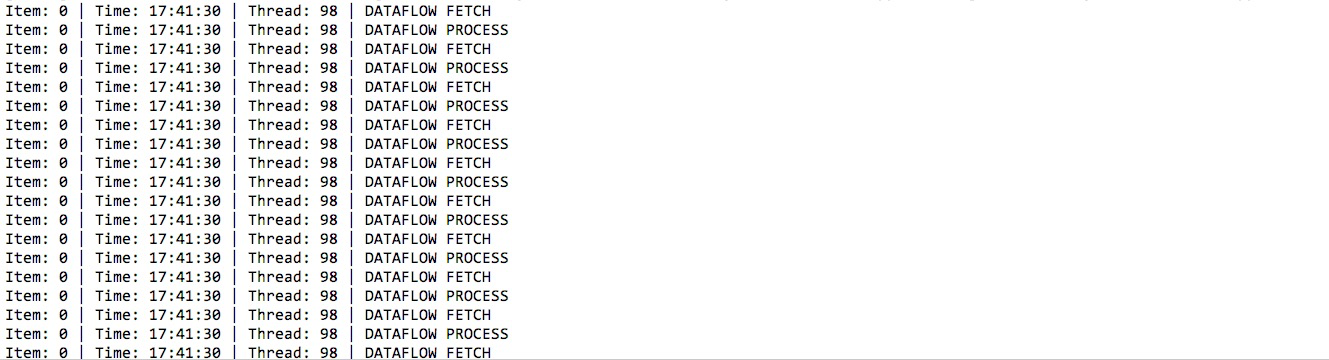
直接启动SpringBoot主类后,任务就会自动加载。
如下图,这里启动了两个端口号不同的作业,相当于是两台单独服务器运行作业,那么每台服务器会单独执行一个分片的作业,这样极大提高了整体业务处理的执行效率。
端口号为8888的作业
端口号为8889的作业

注册中心节点
上述演示的作业的核心配置等最终都会配置到zookeeper的节点中,如下图。
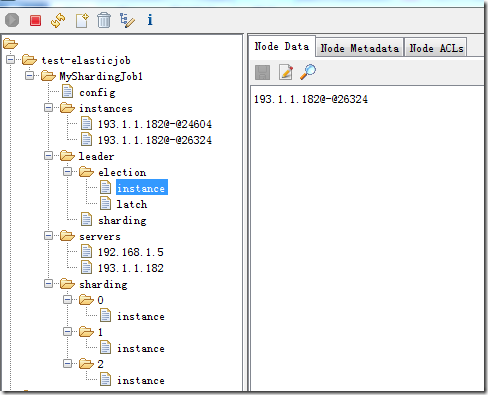
1、config节点
任务的配置信息,包含执行类,cron表达式,分片算法类,分片数量,分片参数等等。config节点的数据是通过ConfigService持久化到zookeeper中去的。默认状态下,如果你修改了Job的配置比如cron表达式,分片数量等是不会更新到zookeeper上去的,除非你把参数overwrite修改成true。
2、instances节点
同一个Job下的elastic-job的部署实例。一台机器上可以启动多个Job实例,也就是Jar包。instances的命名是IP+@-@+PID。
3、leader节点
任务实例的主节点信息,通过zookeeper的主节点选举,选出来的主节点信息。下面的子节点分为election,sharding和failover三个子节点。分别用于主节点选举,分片和失效转移处理。election下面的instance节点显式了当前主节点的实例ID:jobInstanceId。latch节点也是一个永久节点用于选举时候的实现分布式锁。sharding节点下面有一个临时节点,necessary,是否需要重新分片的标记。如果分片总数变化,或任务实例节点上下线或启用/禁用,以及主节点选举,都会触发设置重分片标记,主节点会进行分片计算。
4、servers节点
任务实例的信息,主要是IP地址,任务实例的IP地址。如果多个任务实例在同一台机器上运行则只会出现一个IP子节点。可在IP地址节点写入DISABLED表示该任务实例禁用。 在新的cloud native架构下,servers节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。为了更加纯粹的实现job核心,servers功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。
5、sharding节点
任务的分片信息,子节点是分片项序号,从零开始,至分片总数减一。分片个数是在任务配置中设置的。分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。最主要的子节点就是instance。举例来说,上图有三个分片,每个分片下面有个instance的节点,也就说明了这个分片在哪个instance上运行。如上文所说如果分片总数变化,或任务实例节点上下线或启用/禁用,以及主节点选举,都会触发设置重分片标记,主节点会进行分片计算。分片计算的结果也就体现在这instance上。
运维中心
Elastic-Job-Lite版本提供了运维平台,可以解压缩elastic-job-lite-console-${version}.tar.gz并执行bin\start.sh。打开浏览器访问http://localhost:8899/即可访问控制台。8899为默认端口号,可通过启动脚本输入-p自定义端口号。
elastic-job-lite-console-${version}.tar.gz可通过mvn install编译获取,在本地机器上运行。
登录
提供两种账户,管理员及访客,管理员拥有全部操作权限,访客仅拥有察看权限。默认管理员用户名和密码是root/root,访客用户名和密码是guest/guest,可通过conf\auth.properties修改管理员及访客用户名及密码。
功能列表
- 登录安全控制
- 注册中心、事件追踪数据源管理
- 快捷修改作业设置
- 作业和服务器维度状态查看
- 操作作业禁用\启用、停止和删除等生命周期
- 事件追踪查询
演示图
运维主页面
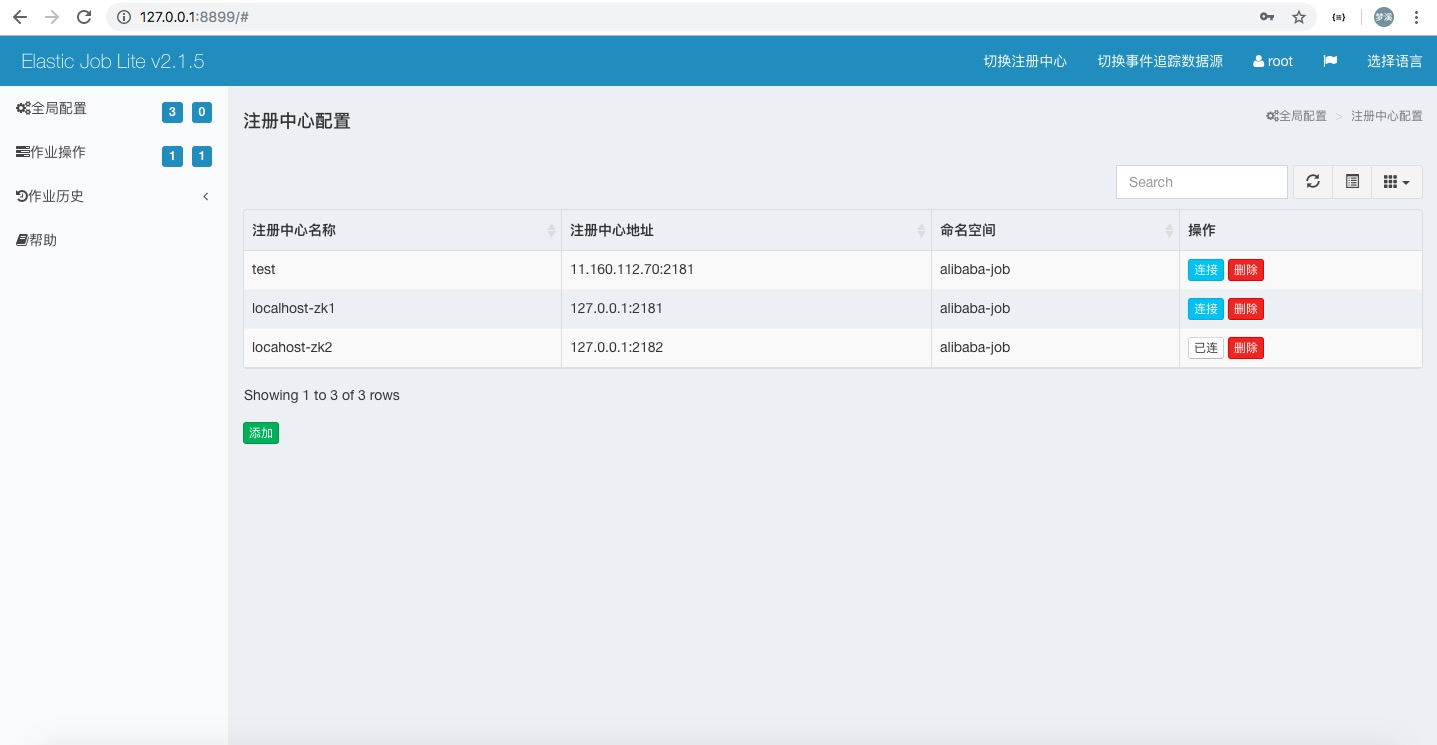
添加注册中心
如下连接本机测试的注册中心,添加测试作业的命名空间elastic-job-lite-springboot,提交后,点击连接。

查看命名空间下的作业
如下图,可以看出该注册中心下的elastic-job-lite-springboot命名空间存在两个作业,列表中的操作列下还可以对作业进行实时的管理。
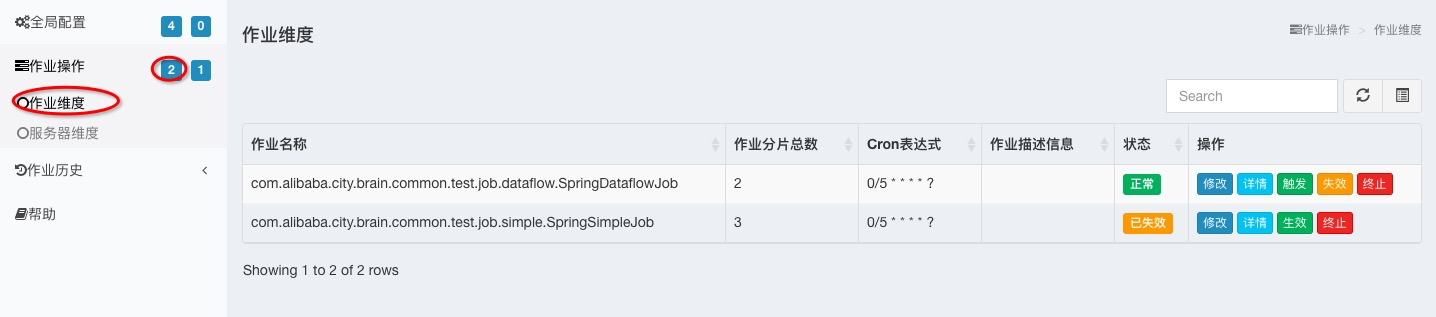
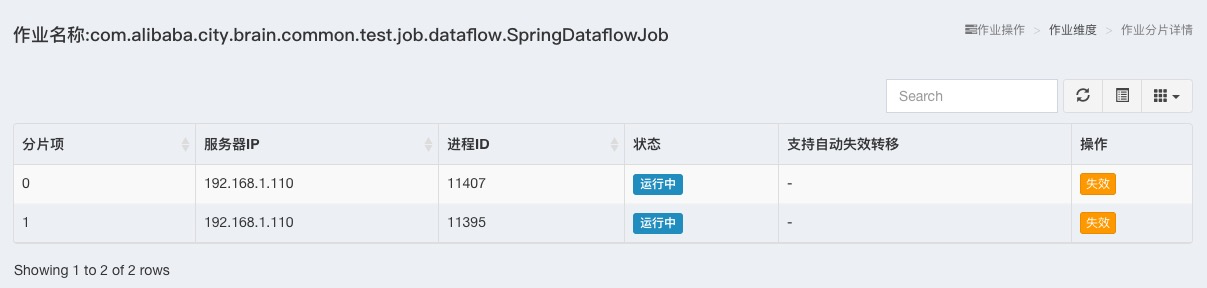
查看单个作业详情
如下图,查看SpringDataflowJob作业,列表中显示了该作业的分片项信息。
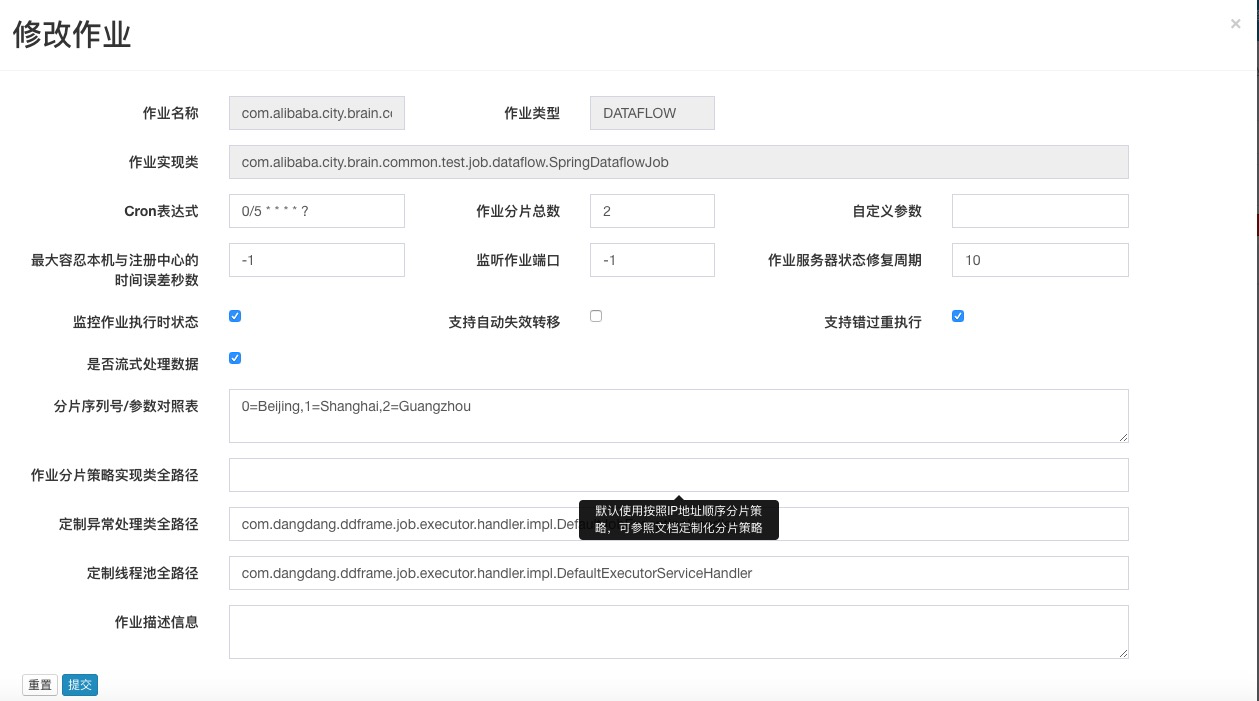
修改作业
如下图,点击修改,可以针对该作业的核心配置、分片、定时信息进行修改。
注意:
该运维平台不支持添加作业,作业在首次运行时将自动添加。Elastic-Job-Lite以jar方式启动,并无作业分发功能。如需完全通过运维平台发布作业,请使用Elastic-Job-Cloud。
项目开源地址
https://github.com/elasticjob/elastic-job-lite
本文参考
http://elasticjob.io/docs/elastic-job-lite/00-overview/
https://www.jianshu.com/p/b91b792f0ac6
https://my.oschina.net/u/719192/blog/506062
- 我的微信
- 加好友一起交流!
-

- 微信公众号
- 关注公众号获取分享资源!
-





2020年3月3日 下午5:02 沙发
流程图和演示图都没有了,大佬补一下吧